This section shows some examples describing how to instantiate advanced kernel functions (such as Sequence Kernels, Tree Kernels and Graph Kernels) in learning algorithms.
Tree Kernels
Several NLP tasks require the explorations of complex semantic and syntactic phenomena. For instance, in Paraphrase Detection, verifying whether two sentences are valid paraphrases involves the analysis of some rewriting rules in which the syntax plays a fundamental role. In Question Answering, the syntactic information is crucial, as largely demonstrated in (Croce et al., 2011). In these scenarios, a possible solution is represented by the manual definition of an artificial feature set that is able to capture the syntactic and semantic aspects useful to solve a target problem. Determining how to exploit these features to generate robust predictive models is left to the learning algorithm. However, the definition of meaningful features is still a rather expensive and complicated process that requires a domain expert; moreover, every task has specific patterns that must be considered, making the underlying manual feature engineering an extremely complex and not portable process. Instead of trying to design a synthetic feature space, a more natural approach consists in applying kernel methods on structured representations of data objects, e.g., documents. A sentence s can be represented as a parse tree that takes into account the syntax of s.
Tree kernels (Collins and Duffy, 2001) can be employed to directly operate on such parse trees, evaluating the tree fragments shared by the input trees. Kernel-based learning algorithms, such as Support Vector Machines (Cortes and Vapnik 1995), can operate in order to automatically generate robust prediction models. Different tree representations embody different linguistic theories and may produce more or less effective syntactic/semantic feature spaces for a given task. Among the different variants discussed in (Croce et al. 2011), we first investigate in this example the Grammatical Relation Centered Tree (GRCT) illustrated below
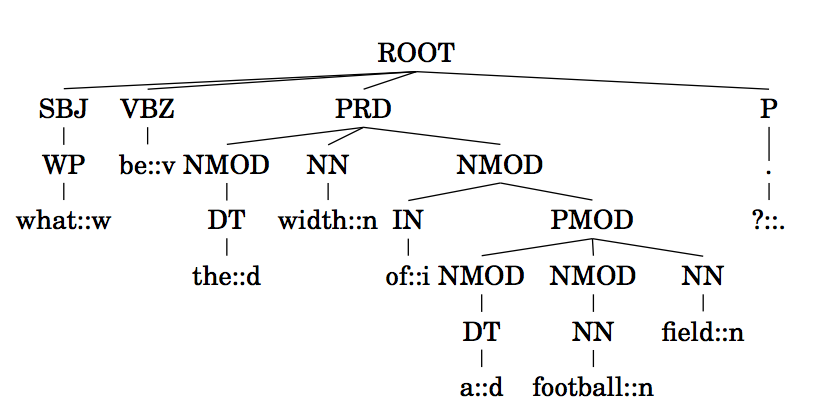
In a nutshell, given a sentence such as “What is the width of a football field ? ” we can use a natural language parser, such as Stanford Parser to extract a Dependency Parse tree, such as
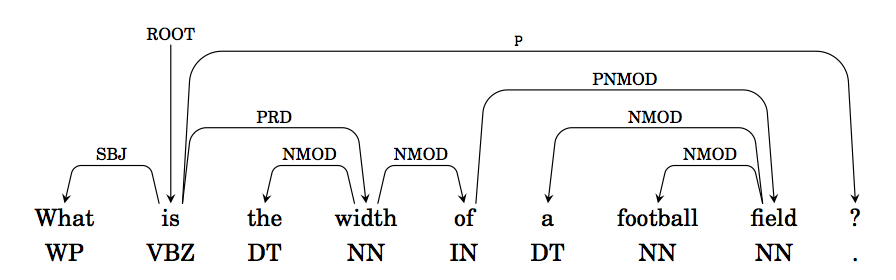
The parse automatically extract linguistic information, such as the Part-of-speech tag (e.g., field is a Noun, whosePart-of-speech tag is NN) or Dependency Relations among words (e.g., football in a Noun Modifier of field). A Dependency Parse tree can be (quite easily) manipulated and converted in tree structures that can be used by tree kernels defined in KeLP (Croce et al, 2011): a GRCT is a tree where PoS-Tags are children of grammatical function nodes and fathers of their associated lexicals.
In order to apply a tree kernel, we first need to load a dataset, where each example contains a Tree Representation. The GRCT representation of the previous parsed sentence is:
|
1 |
NUM |BT:grct| (SYNT##root(POS##WP(LEX##what::w))(SYNT##cop(POS##VBZ(LEX##be::v)))(SYNT##nsubj(SYNT##det(POS##DT(LEX##the::d)))(POS##NN(LEX##width::n))(SYNT##prep_of(SYNT##det(POS##DT(LEX##a::d)))(SYNT##nn(POS##NN(LEX##football::n)))(POS##NN(LEX##field::n))))) |ET| |
The GRCT representation is thus a representation of a tree with round brackets. Note that, the boundaries for a Tree Representation is |BT| |ET|. To automatically generate GRCT representations (or other tree representations) from text snippets please refer to this page. In this example, each question is associated to a class reflecting the aim of the question: in this case the question expects an answer with a number, i.e., NUM.
The :grct are used in KeLP to assign a label to each representation. During the kernel definition phase, these labels are used to indicate which representation must be used during the kernel computation.
The following code, reads a dataset compliant with these representations. Notice that this example is derived from the kelp-full project, from the class
|
1 |
it.uniroma2.sag.kelp.examples.demo.qc.QuestionClassification |
and the training / test dataset are contained in the folder
|
1 |
kelp-full/src/main/resources/qc |
So, first we load the datasets with
|
1 2 3 4 |
SimpleDataset trainingSet = new SimpleDataset(); trainingSet.populate("src/main/resources/qc/train_5500.coarse.klp.gz"); SimpleDataset testSet = new SimpleDataset(); testSet.populate("src/main/resources/qc/TREC_10.coarse.klp.gz"); |
Then we can define a Partial Tree Kernel (PTK, [Moschitti, 2006]) with some default parameters (refers to the documentation for details).
|
1 2 |
// Define a new Partial Tree Kernel Kernel kernel = new PartialTreeKernel(0.4f, 0.4f, 1, "grct"); |
In this example, the learning algorithm used is a SVM implementation based on the C-SVM implementation of LibSVM.
|
1 2 3 4 5 |
// Instantiate a prototype for a binary svm solver BinaryCSvmClassification svmSolver = new BinaryCSvmClassification(); svmSolver.setKernel(kernel); svmSolver.setCp(3); svmSolver.setCn(3); |
The Question Classification task addressed here is a multi-classification problem, where each question has to be associated to one class from a closed set. Here, we introduce also the concept of multi-classification. A One-vs-All classifier is instantiated. It must know what is the base algorithm to be applied, and what are the labels to be learned.
The OneVsAllLearning class will be responsible to “copy” the base algorithms, and to perform the learning according to the One-Vs-All strategy.
|
1 2 3 4 5 6 7 |
// Instantiate a OneVsAll classifier OneVsAllLearning ovaLearner = new OneVsAllLearning(); ovaLearner.setBaseAlgorithm(svmSolver); // get the labels on the training set List<label> labels = trainingSet.getClassificationLabels();</label> ovaLearner.setLabels(labels); ovaLearner.learn(trainingSet); |
Then, a PredictionFunction can be obtained, in particular a OneVsAllClassifier object. This can be easily used to classify each example from the test set and evaluate a performance measure, such as the accuracy.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
OneVsAllClassifier f = ovaLearner.getPredictionFunction(); // Evaluation over the test set int correct = 0; int howmany = testSet.getNumberOfExamples(); for (Example e: testSet.getExamples()) { OneVsAllClassificationOutput predict = f.predict(e); // the OneVsAllClassifer returns a List of predicted Labels, where the first is the argmax if (e.isExampleOf(predict.getPredictedClasses().get(0))) correct++; } float accuracy = (float)correct/(float)howmany; |
The tree kernels introduced in previous section perform a hard match between nodes when comparing two substructures. In NLP tasks, when nodes are words, this strict requirement reflects in a lack a lexical generalization: words are considered mere symbols and their semantics is completely neglected.
To overcome this issue, KeLP also implements more expressive tree kernel functions, such as the Smoothed Partial Tree Kernel (SPTK,[Croce et al. 2011]), that allow to to generalize the meaning of single words by replacing them with Word Embeddings that are automatically derived from the analysis of large-scale corpora. A SPTK can be implemented with the following code:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
String matrixPath = "src/main/resources/wordspace/wordspace_qc.txt.gz"; // The word space containing the vector representation of words // represented in lexical nodes is loaded Wordspace wordspace = new Wordspace(matrixPath); // This manipulator assigns vectors to lexical nodes. It allows // to speed-up computations: otherwise each time the similarity // between two nodes is evaluated, the corresponding vectors are // retrieved in the word space, with additional operational // costs. LexicalStructureElementManipulator lexManipulator = new LexicalStructureElementManipulator(wordspace, grct); trainingSet.manipulate(lexManipulator); testSet.manipulate(lexManipulator); // This class implements a similarity function between lexical // nodes based on the Word space LexicalStructureElementSimilarity similarityWordspace = new LexicalStructureElementSimilarity(wordspace); // The kernel operating over the lct representation Kernel sptklct = new SmoothedPartialTreeKernel(0.4f, 0.4f, 0.2f, 0.01f, similarityWordspace, grct); |
The main limitations of this approach are that (i) lexical semantic information only relies on the vector metrics applied to the leaves in a context free fashion and (ii) the semantic compositions between words is neglected in the kernel computation, that only depends on their grammatical labels.
In [Annesi et al. 2014] a solution for overcoming these issues is proposed. The pursued idea is that the semantics of a specific word depends on its context. For example, in the sentence, “What instrument does Hendrix play?”, the role of the word instrument is fully captured if its composition with the verb play is taken into account. Such reasoning can be embedded directly into the tree structures, such as 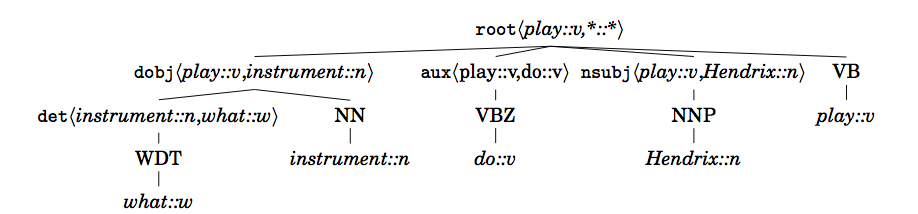
This representation is a compositional extension of the GRCT structure (the cGRCT), where each grammatical function node n is marked adding to its original label  (i.e., the dependency relation it represents) its underlying head/modifier pair
(i.e., the dependency relation it represents) its underlying head/modifier pair  . In this case KeLP implement the Compositionally Smoothed Partial Tree Kernel (CSPTK, [Annesi et al., 2014]), that applies measure of Compositional Distributional Semantics over pairs. It can be used with the following code
. In this case KeLP implement the Compositionally Smoothed Partial Tree Kernel (CSPTK, [Annesi et al., 2014]), that applies measure of Compositional Distributional Semantics over pairs. It can be used with the following code
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
String matrixPath = "src/main/resources/wordspace/wordspace_qc.txt.gz"; Wordspace wordspace = new Wordspace(matrixPath); // This manipulator assigns vectors to lexical nodes. It allows // to speed-up computations: otherwise each time the similarity // between two nodes is evaluated, the corresponding vectors are // retrieved in the word space, with additional operational // costs. LexicalStructureElementManipulator lexManipulator = new LexicalStructureElementManipulator(wordspace, cgrct); trainingSet.manipulate(lexManipulator); testSet.manipulate(lexManipulator); // Compositional nodes syntactic nodes are represented as vector // that is the sum of the vector representing the syntactic head // and modifier, as discussed in (Annesi et al., 2014) CompositionalNodeSimilaritySum compSS = new CompositionalNodeSimilaritySum(); compSS.setWordspace(wordspace); compSS.setRepresentationToBeEnriched(treeRepresentationName); // This manipulator assigns vectors to "compositional syntactic" // nodes. It allows to speed-up computations: otherwise each // time the similarity between two nodes is evaluated, the // corresponding vectors are retrieved in the word space, with // additional operational costs. trainingSet.manipulate(compSS); testSet.manipulate(compSS); // The kernel operating over the clct representation Kernel sptkcgrct = new SmoothedPartialTreeKernel(0.4f, 0.4f, 1f, 0.01f, compSS, treeRepresentationName); |
The SPTK and CSPTK are very promising kernels, as they allow obtaining state-of-the-art results in the Question classification task, i.e., 95% of accuracy over well known datasets.
NOTE: even if very expressive these kernel show a computational complexity that is higher w.r.t. kernels operating over feature vectors. A caching policy is highly recommended.
Sequence Kernels
It will be available soon… stay tuned!
Graph Kernels
Graphs are a powerful way to represent complex entities in learning problems.
This example shows how to apply a graph kernel to a small-sized popular benchmark dataset for graphs: MUTAG (Debnath et al., 1991). The examples are chemical compounds and the task is to discriminate whether they are mutagenic/non-mutagenic.
An example in the dataset has the following form:
|
1 |
1 |BG:inline|1 3&&2 3&&3 3&&4 3&&5 3&&6 3&&7 3&&8 3&&9 3&&10 3&&11 3&&12 3&&13 3&&14 3&&15 3&&16 3&&17 3&&18 3&&19 3&&20 3&&21 6&&22 7&&23 7%%1 2&&1 14&&2 3&&2 1&&3 4&&3 12&&3 2&&4 5&&4 3&&5 6&&5 4&&6 7&&6 11&&6 5&&7 8&&7 21&&7 6&&8 9&&8 7&&9 10&&9 8&&10 11&&10 16&&10 9&&11 12&&11 6&&11 10&&12 13&&12 3&&12 11&&13 14&&13 15&&13 12&&14 1&&14 13&&15 16&&15 20&&15 13&&16 17&&16 10&&16 15&&17 18&&17 16&&18 19&&18 17&&19 20&&19 18&&20 15&&20 19&&21 22&&21 23&&21 7&&22 21&&23 21|EG| |
Notice that the representation delimiters are |BG|, |EG| and the representation name is inline. The task is a binary classification one.
We perform a 10-fold cross validation on MUTAG dataset using two graph kernels.
The following code is derived from the class
|
1 |
it.uniroma2.sag.kelp.examples.demo.mutag.MutagClassification |
in the kelp-full project.
The dataset can be found in the folder
|
1 |
kelp-full/src/main/resources/mutag/mutag.txt |
We start by loading the dataset
|
1 2 3 |
SimpleDataset trainingSet = new SimpleDataset(); trainingSet.populate("src/main/resources/mutag/mutag.txt"); StringLabel positiveClass = new StringLabel("1"); |
Two graph kernels are applied: Weisfeiler-Lehman Subtree kernel (Shervashidze et al., 2011) and the Shortest Path kernel (Borgwardt et al., 2005).
We first extract the features corresponding to the Weisfeiler-Lehman Subtree Kernel for Graphs.
The kernel counts the number of identical subtree patterns obtained by breadth-first visits where each node can appear multiple times. The depth of the visits is a parameter of the kernel, in this example it is set to 4.
The new features that are extracted will be identified by the representation name “wl”
|
1 2 |
WLSubtreeMapper m = new WLSubtreeMapper("inline", "wl", 4); trainingSet.manipulate(m); |
We define next a kernel which combines the Weisfeiler-Lehman Subtree and Shortest Path kernels on the “wl” and “inline” representations. The weights of the combination are 1. We further define a cache for the kernel computations.
|
1 2 3 4 5 6 |
LinearKernelCombination comb = new LinearKernelCombination(); LinearKernel linear = new LinearKernel("wl"); comb.addKernel(1, linear); ShortestPathKernel spk = new ShortestPathKernel("inline"); comb.addKernel(1, spk); comb.setKernelCache(new FixIndexKernelCache(trainingSet.getNumberOfExamples())); |
We define the SVM solver and an utility object for evaluating a binary SVM classifier.
|
1 2 3 |
StringLabel targetLabel = new StringLabel("1"); BinaryCSvmClassification svmSolver = new BinaryCSvmClassification(comb, targetLabel, 1, 1); BinaryClassificationEvaluator evaluator = new BinaryClassificationEvaluator(targetLabel); |
The following code performs the 10-fold cross validation and reports the mean accuracy.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
float meanAcc = 0; int nFold = 10; List<BinaryClassificationEvaluator> evalutators = ExperimentUtils.nFoldCrossValidation(nFold,svmSolver, trainingSet, evaluator); for(int i=0;i<nFold;i++){ float accuracy = evalutators.get(i).getPerformanceMeasure("accuracy"); System.out.println("fold " + (i+1) + " accuracy: " + accuracy); meanAcc+=accuracy; } meanAcc/=(float)10; System.out.println("MEAN ACC: " + meanAcc); |
The mean accuracy over the ten folds is 0.8468714.
References
K. Borgwardt and H.-P. Kriegel, “Shortest-Path Kernels on Graphs,” in ICDM, Los Alamitos, CA, USA: IEEE, 2005, pp. 74–81.
Paolo Annesi, Danilo Croce, and Roberto Basili. Semantic compositionality in tree kernels. In Proceedings of the 23rd ACM International Conference on Conference on In- formation and Knowledge Management, CIKM ’14, pages 1029–1038, New York, NY, USA, 2014. ACM.
Michael Collins and Nigel Duffy. Convolution kernels for natural language. In Proceedings of the 14th Conference on Neural Information Processing Systems, 2001.
Danilo Croce, Alessandro Moschitti, and Roberto Basili. Structured lexical similarity via convolution kernels on dependency trees. In Proceedings of EMNLP, Edinburgh, Scotland, UK., 2011.
Debnath, A.K. Lopez de Compadre, R.L., Debnath, G., Shusterman, A.J., and Hansch, C. (1991). Structure-activity relationship of mutagenic aromatic and heteroaromatic nitro compounds. Correlation with molecular orbital energies and hydrophobicity. J. Med. Chem. 34:786-797.
Alessandro Moschitti. Efficient convolution kernels for dependency and constituent syntactic trees. In ECML, Berlin, Germany, September 2006.
Shervashidze, Nino and Schweitzer, Pascal and van Leeuwen, Erik Jan and Mehlhorn, Kurt and Borgwardt, Karsten M., “Weisfeiler-lehman graph kernels,” JMLR, vol. 12, pp. 2539–2561, 2011.