they are DirectKernels operating on TreeRepresentations. Tree kernels mostly differ on the tree fragments considered when they estimate the similarity between two trees. The following figure exemplifies some possible tree fragments. For more info about tree kernels, please refer to this page. To generate tree data structures from text snippets please refer to this page.
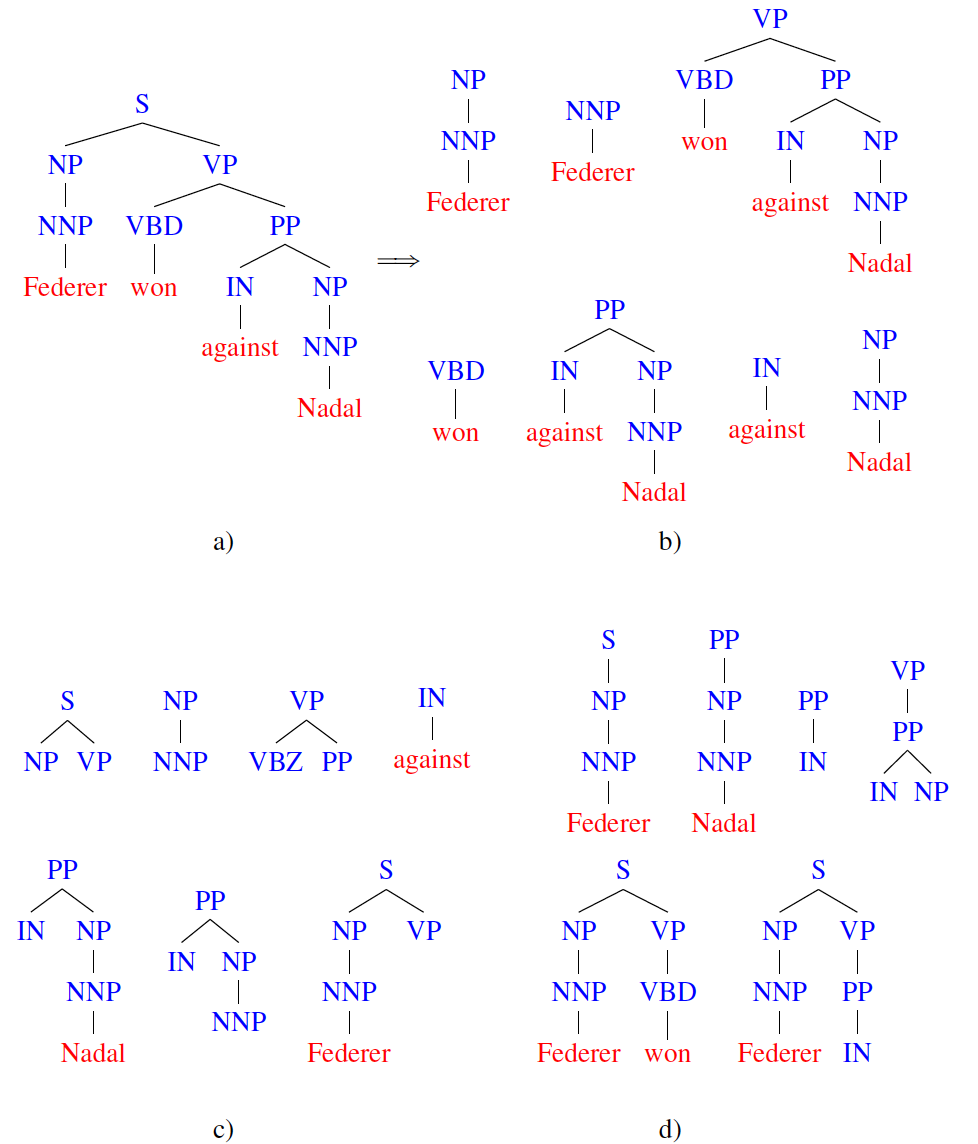
a) Constituency parse tree for the sentence Federer won against Nadal, b) some subtrees, c) some subset trees, d) some partial trees.
Subtree Kernel
Java class: SubTreeKernel
Source code: SubTreeKernel.java
Maven Project: kelp-additional-kernels
JSON type: stk
Description: a SubTree Kernel is a convolution kernel that evaluates the tree fragments shared between two trees. The considered fragments are subtrees, i.e., a node and its complete descendancy. For more details see (Vishwanathan and Smola, 2003).
Parameters:
- representation: the String identifying the representation on which the kernel must operate
- includeLeaves: whether the leaves must be involved in the kernel computation. Regardless its value, two subtrees are matched even if their leaves differ (but the other nodes must match). When it is true, matching leaves contribute to the kernel function; this corresponds to adding a bag-of-words similarity to the kernel function.
- lambda: the decay factor (associated to the height of a subtree).
Subset Tree Kernel
Java class: SubSetTreeKernel
Source code: SubSetTreeKernel.java
Maven Project: kelp-additional-kernels
JSON type: sstk
Description: the SubSetTree Kernel, a.k.a. Syntactic Tree Kernel, is a convolution kernel that evaluates the tree fragments shared between two trees. The considered fragments are subset-trees, i.e., a node and its partial descendancy (the descendancy can be incomplete in depth, but no partial productions are allowed; in other words, given a node either all its children or none of them must be considered). For further details see (Collins and Duffy, 2001).
Parameters:
- representation: the String identifying the representation on which the kernel must operate
- includeLeaves: whether the leaves must be involved in the kernel computation. Regardless its value, two subtrees are matched even if their leaves differ (but the other nodes must match). When it is true, matching leaves contribute to the kernel function; this corresponds to adding a bag-of-words similarity to the kernel function.
- lambda: the decay factor (associated to the height of a subset tree).
Partial Tree Kernel
Java class: PartialTreeKernel
Source code: PartialTreeKernel.java
Maven Project: kelp-additional-kernels
JSON type: ptk
Description: it is a convolution kernel that evaluates the tree fragments shared between two trees. The considered fragments are partial trees, i.e., a node and its partial descendancy (the descendancy can be incomplete, i.e., a partial production is allowed). For further details see (Moschitti, 2006).
Some examples are reported in this tutorial page.
Parameters:
- representation: the String identifying the representation on which the kernel must operate
- includeLeaves: whether the leaves must be involved in the kernel computation. Regardless its value, two subtrees are matched even if their leaves differ (but the other nodes must match). When it is true, matching leaves contribute to the kernel function; this corresponds to adding a bag-of-words similarity to the kernel function.
- lambda: the decay factor (associated to the length of a production, including gaps).
- mu: the decay factor (associated to the height of a partial tree).
- terminalFactor: multiplicative factor to scale up/down the leaves contribution.
- maxSubseqLeng: maximum length of common subsequences considered in the recursion. It reflects the maximum branching factor allowed to the tree fragments.
Smoothed Partial Tree Kernel
Java class: SmoothedPartialTreeKernel
Source code: SmoothedPartialTreeKernel.java
Maven Project: kelp-additional-kernels
JSON type: sptk
Description: it is a convolution kernel that evaluates the tree fragments shared between two trees (Croce et al., 2011). The considered fragments are partial trees (as for the PartialTreeKernel) whose nodes are identical or similar according to a node similarity function: the contribution of the fragment pairs in the overall kernel thus depends on the number of shared substructures, whose nodes contribute according to such a metrics.
Some examples are reported in this tutorial page.
Parameters:
- representation: the String identifying the representation on which the kernel must operate
- includeLeaves: whether the leaves must be involved in the kernel computation. Regardless its value, two subtrees are matched even if their leaves differ (but the other nodes must match). When it is true, matching leaves contribute to the kernel function; this corresponds to adding a bag-of-words similarity to the kernel function.
- lambda: the decay factor (associated to the length of a production, including gaps).
- mu: the decay factor (associated to the height of a partial tree).
- terminalFactor: multiplicative factor to scale up/down the leaves contribution.
- maxSubseqLeng: maximum length of common subsequences considered in the recursion. It reflects the maximum branching factor allowed to the tree fragments.
- nodeSimilarity: it is the similarity function that must be applied when comparing two nodes. In particular, the input function must be an implementation of the StructureElementSimilarityI interface. this interface allows the implementation of similarity functions between StructureElements, i.e., the structure that KeLP associates to each node. content of each node, reflecting the node information. This function should return a similarity score that is a kernel itself, otherwise it is not guaranteed the convergence of several learning algorithms, such as Support Vector Machine. Several similarity functions are included in KeLP. In particular, the LexicalStructureElementSimilarity applies a similarity based on word embeddings, as described in (Croce et al., 2011). Different kernels can be defined by varying this parameter (for instance, see the below Compositionally Smoothed Partial Tree Kernel).
- similarityThreshold: it is a threshold applied to the similarity function, also used to speed up the kernel computation: node pairs whose score is below this threshold are ignored in the evaluation.
Compositionally Smoothed Partial Tree Kernel
Java class: SmoothedPartialTreeKernel in combination with an implementation of CompositionalNodeSimilarity
Maven Project: kelp-additional-kernels
JSON type: sptk
Description: it is an extension of the SmoothedPartialTreeKernel that enable the integration of Distributional Compositional Semantic operators (implemented extending the interface CompositionalNodeSimilarity) into the tree kernel evaluation, by acting both over lexical leaves and non-terminal, i.e. complex compositional, nodes (Annesi et al, 2014).
Some examples are reported in this tutorial page.
Paramenters: this kernel inherits several parameters from the SmoothedPartialTreeKernel
- representation: the String identifying the representation on which the kernel must operate
- includeLeaves: whether the leaves must be involved in the kernel computation. Regardless its value, two subtrees are matched even if their leaves differ (but the other nodes must match). When it is true, matching leaves contribute to the kernel function; this corresponds to adding a bag-of-words similarity to the kernel function.
- lambda: the decay factor (associated to the length of a production, including gaps).
- mu: the decay factor (associated to the height of a partial tree).
- terminalFactor: multiplicative factor to scale up/down the leaves contribution.
- maxSubseqLeng: maximum length of common subsequences considered in the recursion. It reflects the maximum branching factor allowed to the tree fragments.
- nodeSimilarity: it is the similarity function that must be applied when comparing two nodes. In particular, the input function should be an implementation of the CompositionalNodeSimilarity interface. This interface allows the implementation of compositional similarity functions between CompositionalStructureElement. This specific similarity function between the so-called Compositional nodes should return a similarity score that is a kernel itself, otherwise it is not guaranteed the convergence of several learning algorithms, such as Support Vector Machine. Several similarity functions are included in KeLP. In particular, the CompositionalNodeSimilaritySum applies a Compositional similarity based on word embeddings of both head/modifiers elements in a semantic/syntactic pairs, as described in (Annesi et al., 2011), that linearly combines the embedding associated to single head and modifier in the pair. Further implementations of such Compositional similarity functions exist, such as CompositionalNodeSimilarityDilation or CompositionalNodeSimilarityProduct.
- similarityThreshold: it is a threshold applied to the similarity function, also used to speed up the kernel computation: node pairs whose score is below this threshold are ignored in the evaluation.
References
Paolo Annesi, Danilo Croce, and Roberto Basili. Semantic compositionality in tree kernels. In Proceedings of the 23rd ACM International Conference on Conference on In- formation and Knowledge Management, CIKM ’14, pages 1029–1038, New York, NY, USA, 2014. ACM.
Michael Collins and Nigel Duffy. Convolution kernels for natural language. In Proceedings of the 14th Conference on Neural Information Processing Systems, 2001.
Danilo Croce, Alessandro Moschitti, and Roberto Basili. Structured lexical similarity via convolution kernels on dependency trees. In Proceedings of EMNLP, Edinburgh, Scotland, UK., 2011.
Alessandro Moschitti. Efficient convolution kernels for dependency and constituent syntactic trees. In ECML, Berlin, Germany, September 2006.
S.V.N. Vishwanathan and A.J. Smola. Fast kernels on strings and trees. In Proceedings of Neural Information Processing Systems (NIPS), 2003.